Most software development teams have adopted continuous integration and delivery (CI/CD) to iterate faster. However, a machine learning model depends not only on the code but also the data and hyperparameters. Releasing a new machine learning model in production is more complex than traditional software development.
Machine learning engineers are still discussing what CI/CD in machine learning actually means and which tools to use. Most machine learning teams use several tools to stitch together their own process to release a new model – updates are released monthly and less daily – which is not the optimal way.
In a previous article , I trained a machine learning model on 4M Reddit posts to classify a post into a subreddit. A month later, I noticed that topics on Reddit evolved, and I needed to collect new data to retrain the model. In this article, I go through the steps to release a new version, describe how to build a CI/CD pipeline for this kind of project, and why it’s essential to retrain models often in machine learning.
A Need for Continuous Integration Arises
To collect the 1k newest posts for the 5k most popular subreddits, I created two CLIs that use the Python Reddit API Wrapper. I store the data in an SQLite database.
Previously, I trained a text classifier with fastText and reported an f1-score of 0.4 and a recall@5 of 0.6 on the test split . That means that about two-thirds of the time, the first five predictions include the subreddit chosen by the human on the test dataset.

End-to-end ML pipeline generated from dependencies between data artifacts, executions and API endpoints.
There are several reasons why the performance on the test split may not represent the performance for new data. For example, it’s expected that the topics that users post on certain subreddits will change with time. In machine learning, that is known as concept drift, and to avoid concept drift, one needs to regularly retrain and release a new version of the model.
Concept drift means that the statistical properties of the target variable change over time in unforeseen ways. Wikipedia
Collecting User Feedback for Machine Learning Models
To collect user feedback, I deployed the model as an API and the Valohai team crafted a UI to interact with the model. I shared the UI on Hacker News . Below you can compare the distribution of p@1 (probability given by the model for the first prediction being right) for the test data and the 8k user submissions .

The average p@1 is 0.549 for the test data and 0.531 for the user submissions. I was surprised to see that the probabilities were so close, meaning that the model was achieving similar certainty levels . If those values are too far away, it means that the model was trained on data that is not representative of the real usage.
In the previous article , I reported that f1-scores were positively correlated with p@1 but slightly lagging behind. Thus, the probability given by the model can be used as a proxy to estimate the f1-score when the label is not known. Below, a p@1 of 0.55 corresponds to an f1-score of 0.4.

It’s important to not only rely on quantitative tests to build your confidence about a machine learning model. Comments on Hacker News were mostly positive, but also raised some cases where the model did not work. Few people reported that it didn’t work for some subreddits. In most of the cases, the model was not trained on those subreddits as they were not part of the most popular ones. That’s hard to measure quantitatively but important to know.
Tried to find /r/DevelEire using the search terms "Irish Software Developers". No luck but Google will bring it up as a first result if the query is "Irish Software Developers Reddit". Hacker News discussion
There was also a comment suggesting a more complex model.
One place to improve this would be to use a better set of word-embeddings. FastText is, well, fast, but it's no longer close to SOTA. You're most likely using simple average pooling, which is why many users are getting results that don't look right to them. Try a chunking approach, where you get a vector for each chunk of the document and horizontally concatenate those together (if your vectors are 50d, and do 5 chunks per doc, then you get a 250d fixed vector for each document regardless of length). This partially solves the issue of highly diluted vectors which is responsible for the poor results that some users are reporting. You can also do "attentive pooling" where you pool the way a transformer head would pool - though that's an O(N^2) operation so YMMV. Hacker News discussion
At this point, I can either build a more complex model that might perform better or simply collect more data. More data tends to have a higher impact on performance than a better model . On production machine learning, avoiding complexity is key to be able to iterate quickly and reduce the cost of maintaining models.
There is a third way to improve the model in the long term, building a continuous integration and delivery pipeline to periodically retrain the model with new data so that performance does not deteriorate with time.
Measuring Concept Drift
To measure concept drift, I collected the latest Reddit submissions one month after I trained the first model.

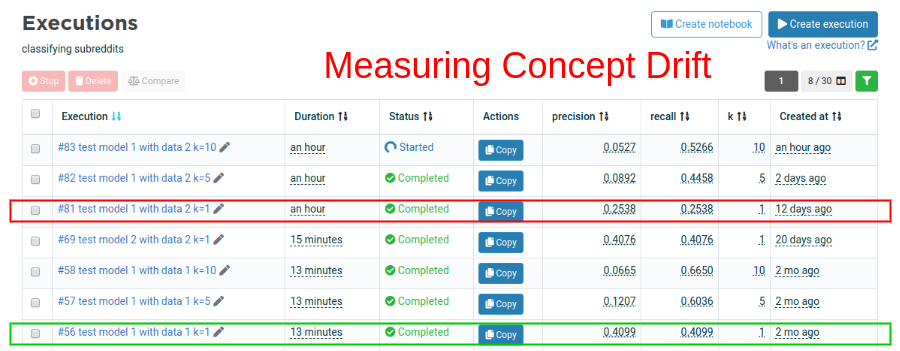
I exported the new submissions for older subreddits and compared the f1-scores between the test and the new data. With Valohai I can run version-controlled executions and compare them on a single interface. When working in a team, this avoids falling into a situation where a team member runs an experiment locally and reports different results. But you ignore for which dataset, code and parameters. In a team, if it’s not version controlled, it’s like it didn’t happen.
 Comparing execution #56 with execution #81, I see that recall went down from 0.40 to 0.25 . The model is not performing as well on new data. The model is aware of it as it can also be seen on the distribution of p@1 on the new data.
Comparing execution #56 with execution #81, I see that recall went down from 0.40 to 0.25 . The model is not performing as well on new data. The model is aware of it as it can also be seen on the distribution of p@1 on the new data.

After retraining on the new data in execution #69, the new model achieves a similar 0.40 recall on the new test data. The new model was trained on an extra 700 subreddits, making it also more useful for the end-user.
In reality, the performance of the model on new data is lower than 0.4 as I split the data randomly into train, validation and test. A chronological split is better, training on older data and testing on the most recent data. As Szilard Pafka pointed on Twitter :
You should measure accuracy on a time-ordered test set. This "actual" accuracy will be typically lower than than the accuracy you get with standard cross-validation. Don't fool yourself, the time-gapped accuracy will be the one you'll actually get when you deploy your model in production and start using it on truly new data.

I was certainly fooled, but I would add that when doing machine learning in production getting a better theoretical accuracy is not your end goal. The important thing is to use the same metric to compare each version-controlled experiment.
At the end, it’s up to your business and end-users to decide whether your machine learning model is useful or not . If Reddit deployed such a model, the usefulness of the model could be measured as the percentage of users that select a subreddit suggested by the model.
Continuous Integration for Machine Learning
Continuous integration in machine learning means that each time you update your code or data, your machine learning pipeline reruns . Integration is done before releasing a new model to validate the latest data and code. I have not set it up for this project yet, but this is how I plan to do it with Valohai.
Valohai comes with an open API that I can use to trigger machine learning executions and pipelines when pushing new code. For example, I can define a Github action to trigger a Valohai execution for every commit. I can also create specific rules to only trigger executions for specific commits and decide which execution to run based on the modified code in the machine learning repository. If your data is continuously getting updated you may want to only retrain models periodically.
You can measure concept drift with a proxy such as p@1 and release new versions before there is a significant performance loss . You can also use Github actions to periodically schedule a workflow to run the machine learning pipeline on Valohai with the latest data.
Machine Learning Model Validation
Most machine learning teams don't deploy to production without some human validation. For example, comparing different reports for the production model and the new model candidate.
To build confidence about a new model you can apply it to all historical data and compare the predictions. Results should not be completely different. Then, you can inspect the data slices for which the performance has significantly changed .
For the subreddit classifier, I compared the performance for each label. Below, you can see how f1-scores decreased significantly for subreddits about politics when I use the old model with the latest data. **
**

f1-score_diff is the f1-score when applying the old model to the new data = diff(data 2, data 1)
After retraining the model with the new data, I notice a smaller performance loss and a slight improvement for r/ukpolitics. There are also two new subreddits: r/NeutralPolitics and r/moderatepolitics.

Overall, the f1-score_change distribution follows a normal distribution around 0. Most subreddits have a performance change between -20% and +20%. The new model is still accurate and more useful as it was trained on more subreddits. I am now confident to release a new version of the machine learning model.
 Continuous Delivery for Machine Learning
Continuous Delivery for Machine Learning
Ideally, you can first deploy your model to your staging environment and let it run for some days. You can also soft release your new model to a subset of users with a canary release.
Valohai helps you create different releases for your machine learning API and easily rollback if necessary. Releasing a new model as an API endpoint is as simple as creating a new version with a model artifact generated by an execution. After having tested the new version, you just need to change the alias for the production release.
 To release a new version, I change the alias from ‘production → 20200331.0’ to ‘production → 20200602.0’.
To release a new version, I change the alias from ‘production → 20200331.0’ to ‘production → 20200602.0’.
Conclusion
Retraining a machine learning model is important when data properties change to overcome concept drift. To eventually achieve CI/CD in machine learning, you can start by automating some parts of your current process.
First, it helps to version data, code and parameters for each machine learning execution and attach the results to your pull requests. Then, you can create end-to-end machine learning pipelines with Valohai that are triggered externally when code and data change. Finally, you can create parameterized reports to run with the latest data.
Valohai already provides version control for machine learning executions, data, pipelines and API deployments that simplifies integrating and deploying new models in production. Valohai includes hosted Jupyter Notebooks to version control all your machine learning code and easily make notebook experiments part of the company-wide production pipeline.
If you are looking to learn more about how to start with CI/CD for Machine Learning and MLOps, see our article: How to Get started with MLOps .