
We’re seeing plenty of tailwinds for open-source LLMs. New open-source entrants, such as Mistral 7B and LLaMa 2, are proving to be worthy contenders to GPT-4 and other proprietary models. While proprietary models may still have an edge in how well they perform in a wide variety of tasks, open-source has an ace up its sleeve. It’s the fact that you can fine-tune for your specific job, deploy these models on your own infrastructure, and have ownership of the fine-tuned model.
We’ve built a template for fine-tuning Mistral 7B on Valohai. Mistral is an excellent combination of size and performance, and by fine-tuning it using a technique called LoRA, we can be very cost-efficient. Check out these links for more details on Mistral 7B and LoRA, respectively.
Now, let’s look at how the Valohai Mistral 7B template works.
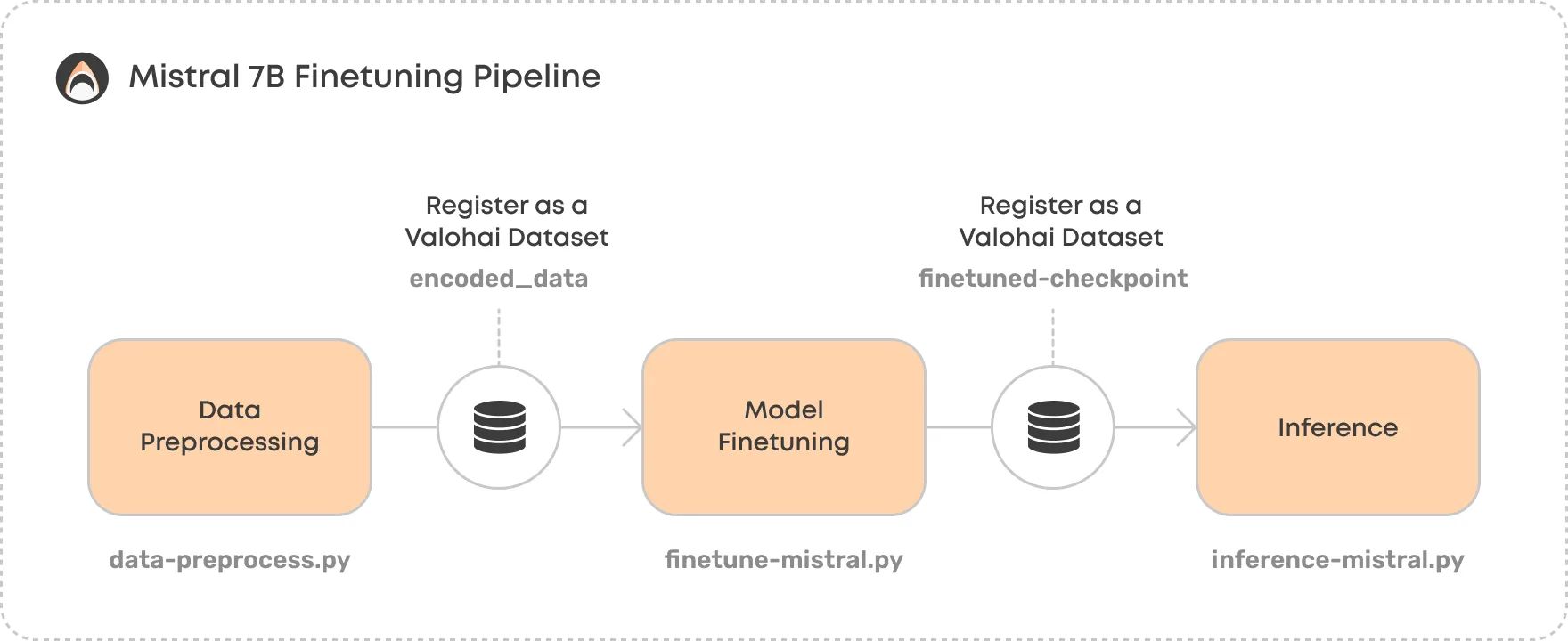
The central part of the template is the fine-tuning pipeline containing the following steps:
1. Data Preprocessing (See code)
This step ingests the files you choose, tokenizes the contents and registers the encoded data as a Valohai Dataset. Datasets are a great way to stay organized and version your data.
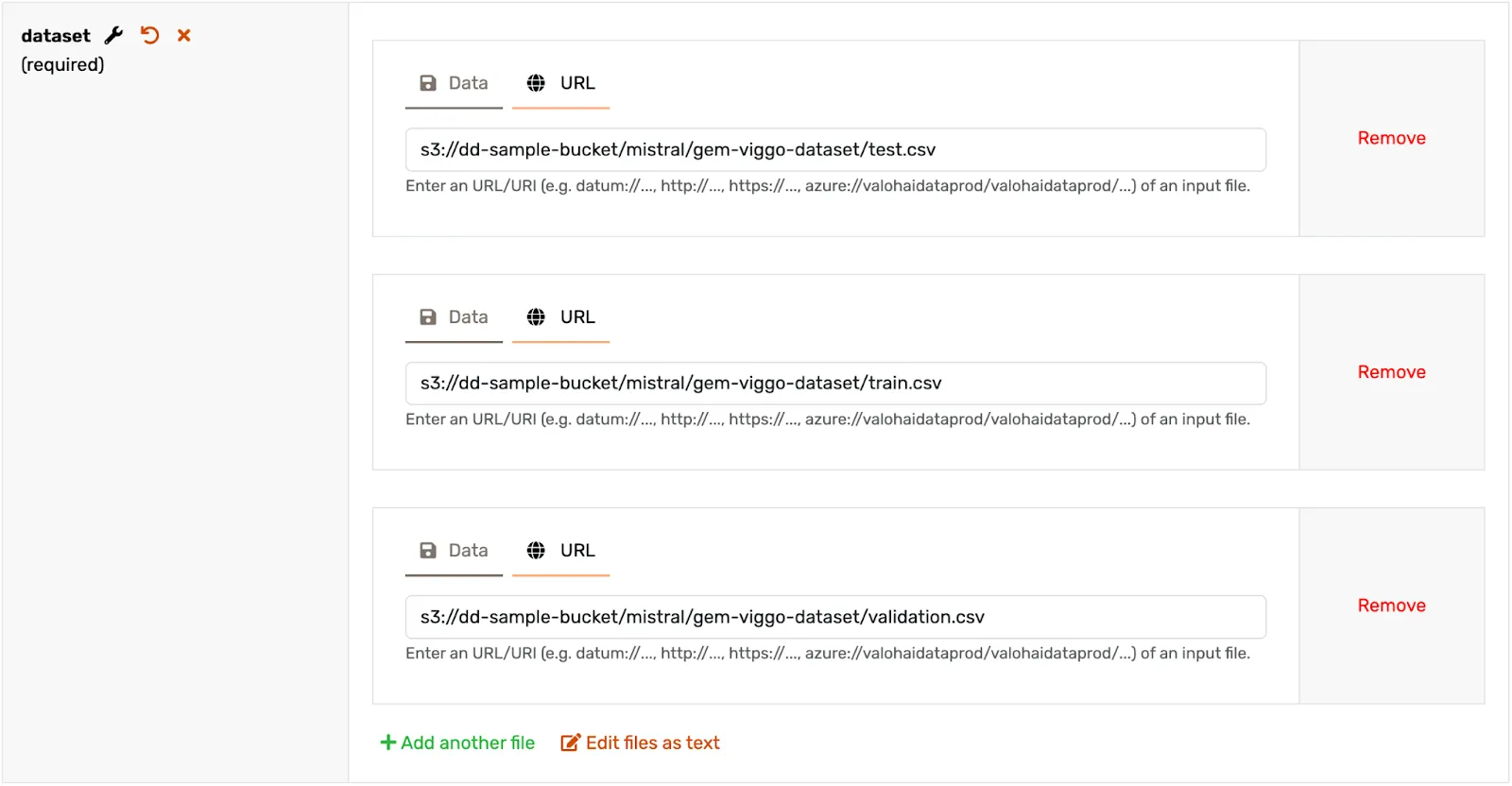
As a sample dataset for the template, We’re using ViGGO. It’s a small but very clean dataset with meaning representations and target sentences. The concept is to transform dense information into natural language.
| gem_id | meaning_representation | target | references |
|---|---|---|---|
| viggo-train-0 | inform(name[Dirt: Showdown], release_year[2012], esrb[E 10+ (for Everyone 10 and Older)], | ||
| genres[driving/racing, sport], platforms[PlayStation, Xbox, PC], available_on_steam[no], has_linux_release[no], | |||
| has_mac_release[no]) | Dirt: Showdown from 2012 is a sport racing game for the PlayStation, Xbox, PC rated E 10+ (for | ||
| Everyone 10 and Older). It’s not available on Steam, Linux, or Mac. | [ “Dirt: Showdown from 2012 is a sport racing | ||
| game for the PlayStation, Xbox, PC rated E 10+ (for Everyone 10 and Older). It’s not available on Steam, Linux, or | |||
| Mac.” ] | viggo-train-1 | inform(name[Dirt: Showdown], release_year[2012], esrb[E 10+ (for Everyone 10 and Older)], | |
| genres[driving/racing, sport], platforms[PlayStation, Xbox, PC], available_on_steam[no], has_linux_release[no], | |||
| has_mac_release[no]) | Dirt: Showdown is a sport racing game that was released in 2012. The game is available on | ||
| PlayStation, Xbox, and PC, and it has an ESRB Rating of E 10+ (for Everyone 10 and Older). However, it is not yet | |||
| available as a Steam, Linux, or Mac release. | [ “Dirt: Showdown is a sport racing game that was released in 2012. The | ||
| game is available on PlayStation, Xbox, and PC, and it has an ESRB Rating of E 10+ (for Everyone 10 and Older). | |||
| However, it is not yet available as a Steam, Linux, or Mac release.” ] | viggo-train-2 | inform(name[Dirt: | |
| Showdown], release_year[2012], esrb[E 10+ (for Everyone 10 and Older)], genres[driving/racing, sport], | |||
| platforms[PlayStation, Xbox, PC], available_on_steam[no], has_linux_release[no], has_mac_release[no]) | Dirt: Showdown | ||
| is a driving/racing sport game released in 2012. It is rated E 10+, and is available on PlayStation, Xbox and PC, but | |||
| not on Steam, Mac, or Linux. | [ “Dirt: Showdown is a driving/racing sport game released in 2012. It is rated E 10+, | ||
| and is available on PlayStation, Xbox and PC, but not on Steam, Mac, or Linux.” ] |
Using this dataset, we can fine-tune our Mistral 7B to replicate the data-to-sentence style. Transferring style is one of the most potent use cases for fine-tuning and doesn’t require enormous datasets.
Of course, this dataset is a placeholder, and you’d replace it with your data that is designed for your use case. For example, if you’d be fine-tuning the LLM for a chatbot, you’d build a dataset containing expected inputs and desired outputs.
2. Model Fine-tuning (see code)
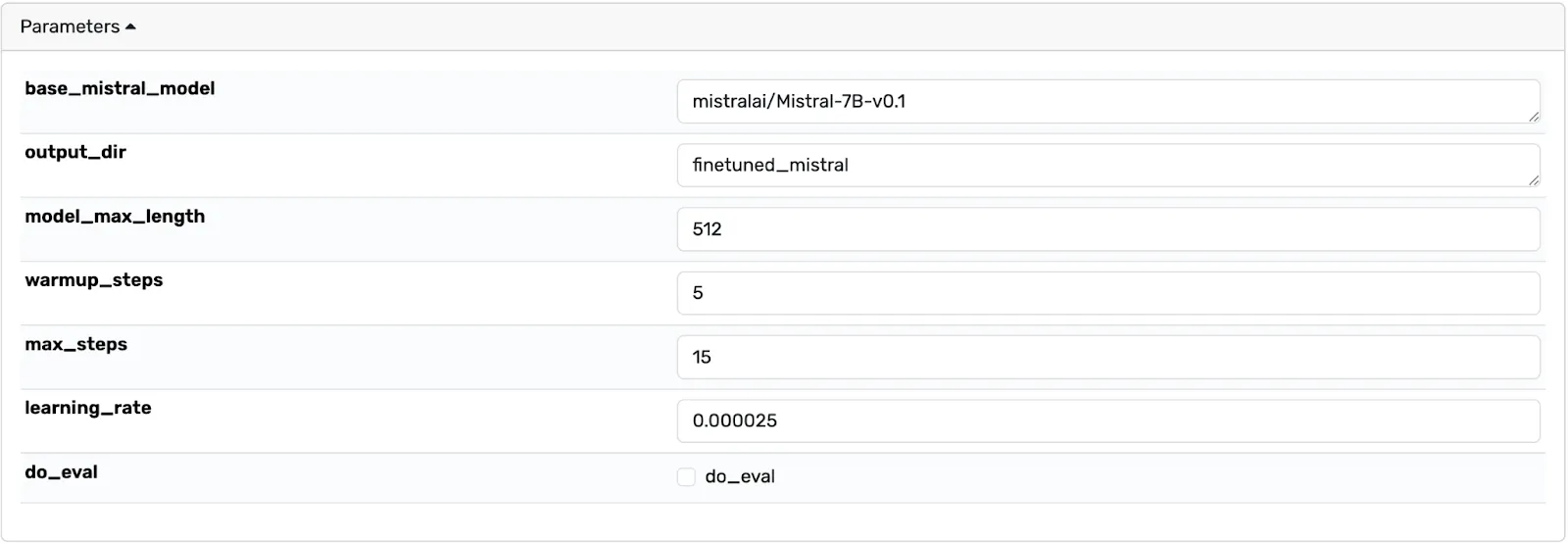
This step fetches the base model automatically and creates a fine-tuned version using the LoRA technique. LoRA is a technique that helps improve and fine-tune large language models while using far fewer parameters, making them more efficient and faster. The template exposes specific parameters, such as learning rate and epochs, that you can play around with to achieve the desired result. The default values are optimized for a quick run, and you’ll want to edit them for a better-performing model.
While the fine-tuning runs, you’ll see metrics, such as loss, in real-time. These metrics can tell you whether the fine-tuning is progressing in the right direction and whether you should continue or cancel the run.
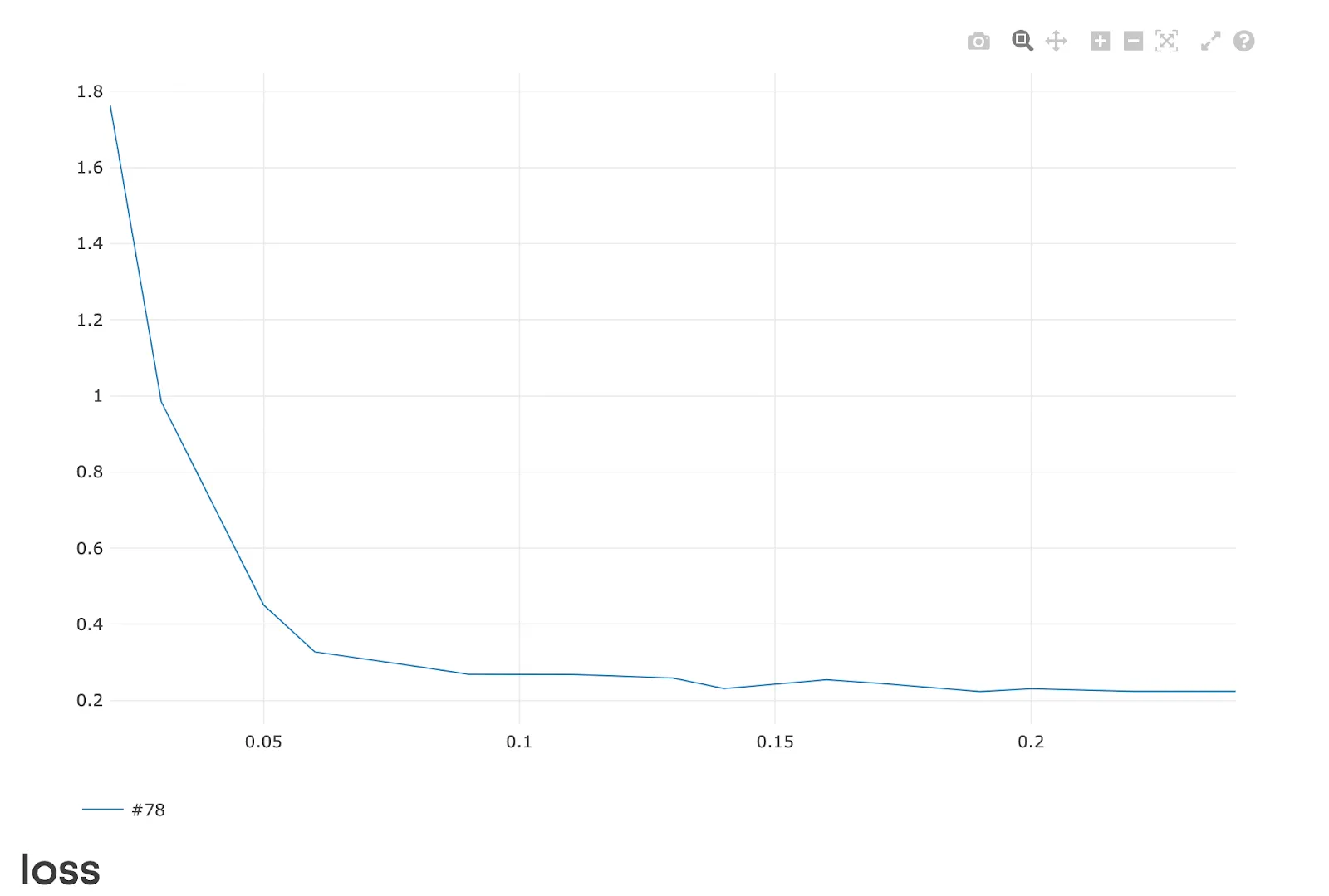
With the default parameters and machines we enabled for trial users in Valohai, the fine-tuning takes approximately 3 hours to complete (and costs a mere $1.5), which speaks to the efficiency of using LoRA.
Finally, the fine-tuned model is saved as a Valohai Dataset to make it easy to version as a package and use downstream.
3. Inference (see code)
This step uses the fine-tuned model from the previous step and tests it with a few prompts. You’ll be able to see how your version of Mistral 7B responds.
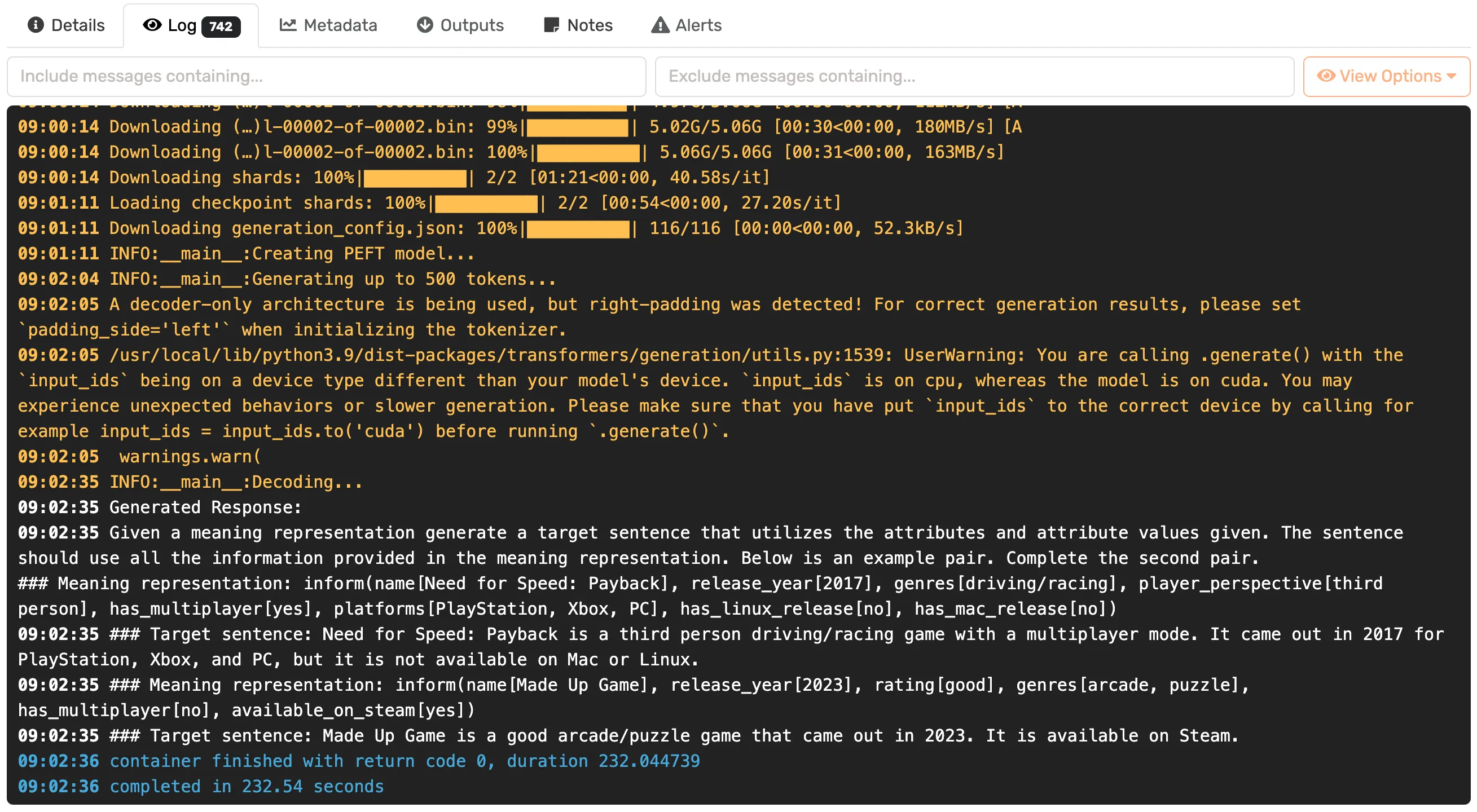
After running the pipeline using your data, you’ll have a versioned dataset (to reproduce a previous checkpoint consistently) and a fine-tuned model ready to be deployed. We’ve also added a simple step that can be used to prompt your newly trained model and test out how it performs with new tasks.
The fastest way to finetune Mistral 7B is to sign up for a Valohai trial and pick the Valohai Mistral 7B template as your first project.

As with all of our templates, it’s also open-source and freely available on GitHub, so you can always fork it and adjust it as you see fit.