You're evaluating claude-sonnet-4.6.
See which one wins.
Compare accuracy, latency, and cost across models and configs. Track every LLM evaluation with 3 lines of Python. Share one link when stakeholders ask "why this model?"
Free while it lasts. No credit card.
A couple of lines of Python. That's it.
pip install valohai-llmimport valohai_llm
valohai_llm.post_result(
task="my-llm-eval",
labels={"model": "gpt-5.2", "category": "billing"},
metrics={"relevance": 0.92, "latency_ms": 340}
)Built by the Valohai team








New models launch every month.
Your evaluation process shouldn't take that long.
Your team's prototype works great on GPT-5. But now you need to decide what to ship at scale. Someone suggests Claude. The infra lead pushes for self-hosted Llama. Finance wants cost projections before anyone commits. The evaluation data to answer these questions is scattered across scripts and spreadsheets.
This keeps happening
- A 2% accuracy difference could save $50k/year in API costs. Or it could be noise. Without structured tracking, you genuinely can't tell.
- GPT-4o's API was retired in February 2026. You had 30 days to re-evaluate everything. Manual wrangling took 3 weeks.
- 70% of your queries probably don't need the expensive model. You just can't prove it without running every combination across your test set.
What you actually need
- Every eval result captured automatically. No more copy-pasting into spreadsheets.
- Side-by-side comparisons across any dimension: model, prompt, temperature, dataset category.
- One URL your whole team can share when someone asks "why this model?" Yes, even finance.
How it works
pip install, post results, compare in browser. No infrastructure to manage.
Install and post results
pip install valohai-llm and call post_result() from your evaluation script. Three lines of code. Results stream in automatically.
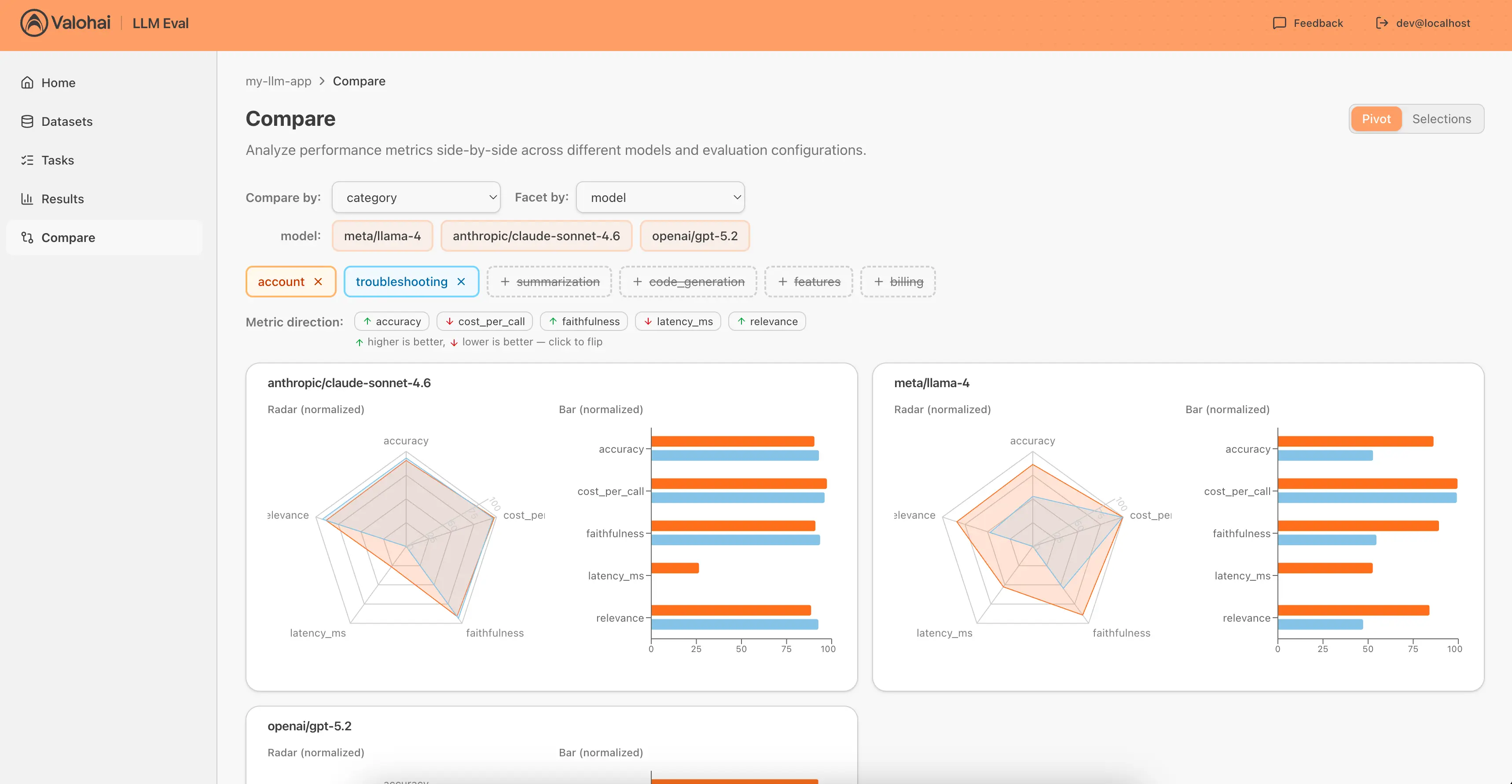
Compare side by side
Filter by any label, group by any dimension. Compare up to 6 configurations with radar charts, bar charts, and scorecards. See differences instantly.
Scale with parameter sweeps
When you're ready, define a parameter grid and a dataset. Valohai LLM runs every combination for you. No loops to write, results posted with labels.
Example
Which LLM should power your support bot?
Three models. Four ticket categories. 60 evaluations. One task definition. Results stream in automatically.
- Grouped by model: quality and cost tradeoffs at a glance.
- Grouped by model + category: Llama 3 matches GPT-4o on simple tickets but drops on complex ones.
- The decision: Route simple tickets to Llama 3, complex ones to Claude. API costs drop 60%.
From first evaluation to business decision in minutes. Not days.
Beyond evals
When evaluations become pipelines
Your eval data tells you which model wins. But shipping that model means automated RAG pipelines, dataset versioning, human approval gates, and reproducible retraining. Across millions of documents, not hundreds of test cases.
That's the full Valohai platform. Same team, same lineage, bigger scale.
Talk to us about LLM pipelines- Automated RAG pipelinesEmbed, retrieve, generate, evaluate. Each step versioned and reproducible.
- Dataset versioningFreeze your eval set, track incremental updates, re-run old experiments against new models.
- Human approval gatesAutomated quality checks with manual sign-off before anything hits production.
- Any model, any infraSwap OpenAI for Azure, Claude, or self-hosted Llama without re-engineering your pipeline.
Your next model decision should take minutes, not weeks.
Install the library, post your first evaluation results, and compare configurations in one dashboard.
Start FreeFree while it lasts. No credit card.