See which one wins.
Compare accuracy, latency, and cost across models and configs. Track every LLM evaluation with 3 lines of Python. Share one link when stakeholders ask "why this model?"
Typical use cases
You're choosing between models for a RAG-powered support bot.
- Manual spot-testing on a few tickets feels productive but gives you basically no reliable signal
- The real issue is that models diverge on hard tickets. Simple lookups score fine across the board, complex reasoning is where you’ll actually see the gaps
- Run all your candidates against your real ticket dataset, slice by category and difficulty, and see the tradeoffs laid out in one place. Then you can make the call with actual data.
You need an LLM to summarize contracts or legal documents and you need to trust what it produces.
- The tricky part is that bad output doesn’t look bad. Models miss liability clauses or drop carve-outs while producing perfectly clean-looking text
- Faithfulness failures are invisible without measurement, and that’s exactly where teams get burned
- Score your models on faithfulness and completeness against real document samples. You’ll quickly see which ones you’d actually trust before they go anywhere near a client.
You tweaked your system prompt and it feels better. Now you need to know if it actually is.
- The frustrating thing is you probably improved some cases and regressed others without realizing it
- Without tracking, prompt changes are basically vibes. You’ll find out what broke in production, not before
- Compare every version across your full test set and see exactly which cases improved and which regressed. Ship with a real diff, not a gut feel.
You're evaluating LLMs for clinical note summarization or documentation workflows.
- Standard benchmarks won’t tell you much here. They don’t reflect your actual documents or the edge cases that matter in your context
- A model that scores well on general evals can still drop critical details on complex cases. In clinical workflows completeness is not a nice to have
- Evaluate against your own document types, score on the dimensions that actually matter, and have something concrete to show compliance when they ask.
Your RAG pipeline is underperforming and you're trying to figure out where to focus.
- The annoying part is you can’t tell whether retrieval or the LLM is the weak link just by looking at outputs
- A lot of models will silently ignore retrieved context and fall back on what they already know. So you get confident-sounding wrong answers even when the right chunks are sitting right there in the prompt
- Hold retrieval constant, swap the LLMs, and see clearly which layer is actually failing. Saves you from optimizing the wrong thing.
Free while it lasts. No credit card.
Built by the Valohai team







New models launch every month. Your evaluation process shouldn’t take that long.
Your team’s prototype works great on GPT-5. But now you need to decide what to ship at scale. Someone suggests Claude. The infra lead pushes for self-hosted Llama. Finance wants cost projections before anyone commits. The evaluation data to answer these questions is scattered across scripts and spreadsheets.
This keeps happening
- A 2% accuracy difference could save $50k/year in API costs. Or it could be noise. Without structured tracking, you genuinely can't tell.
- GPT-4o's API was retired in February 2026. You had 30 days to re-evaluate everything. Manual wrangling took 3 weeks.
- 70% of your queries probably don't need the expensive model. You just can't prove it without running every combination across your test set.
What you actually need
- Every eval result captured automatically. No more copy-pasting into spreadsheets.
- Side-by-side comparisons across any dimension: model, prompt, temperature, dataset category.
- One URL your whole team can share when someone asks "why this model?" Yes, even finance.
How it works
pip install, post results, compare in browser. No infrastructure to manage.
Install and post results
pip install valohai-llm and call post_result() from your evaluation script. Three lines of code. Results stream in automatically.
Compare side by side
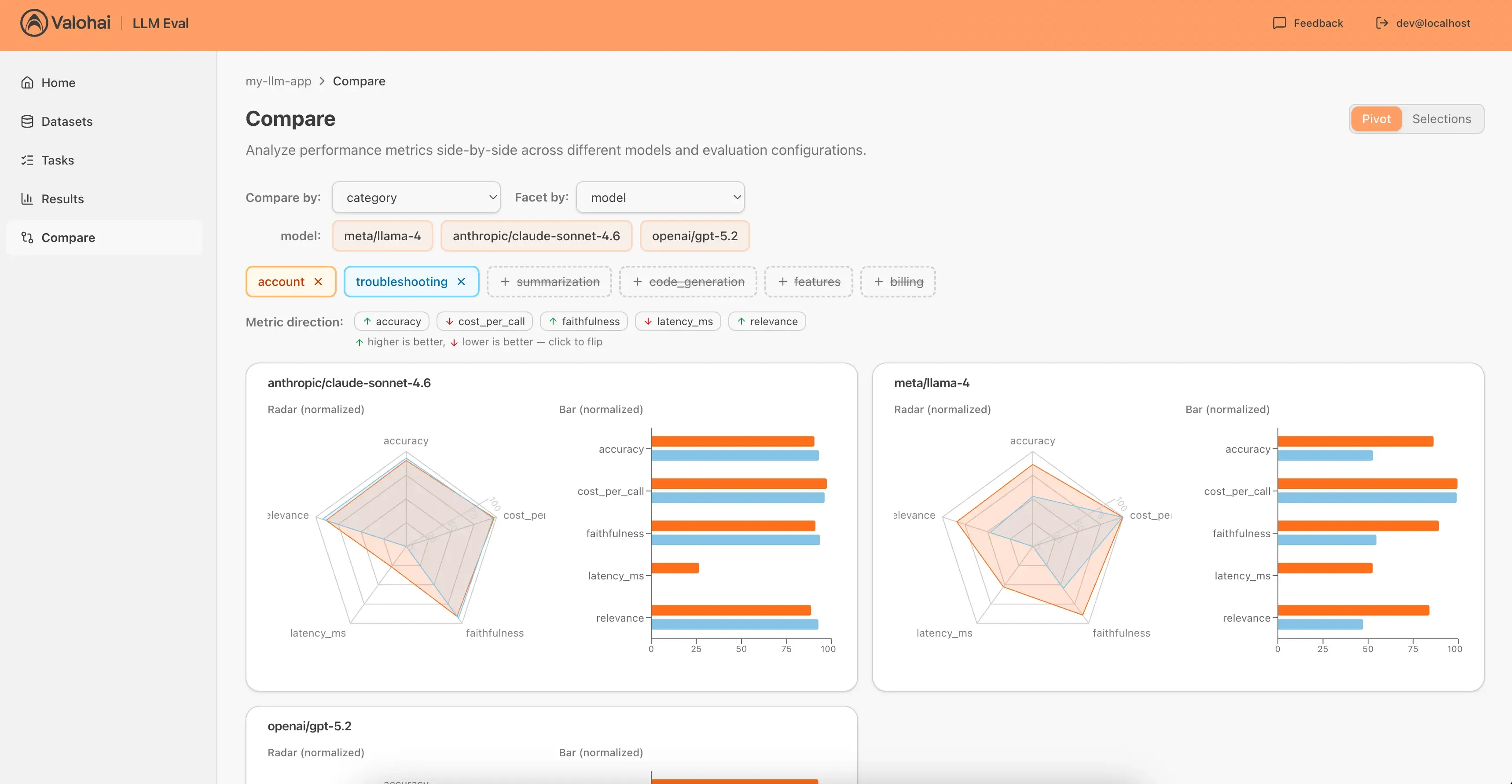
Filter by any label, group by any dimension. Compare up to 6 configurations with radar charts, bar charts, and scorecards. See differences instantly.
Scale with parameter sweeps
When you're ready, define a parameter grid and a dataset. Valohai LLM runs every combination for you. No loops to write, results posted with labels.
Your next model decision should take minutes, not weeks.
Start FreeFree while it lasts. No credit card.